Modul 4: Normalisierungen
Die Drei Normalformen
Die drei Normalformen bauen aufeinander auf. Das bedeutet, dass jede Tabelle, die nach der 2. Normalform normalisiert
ist, auch nach der 1. normalisiert ist. Auch Tabellen in der 3. Normalform sind nach der 2. und folglich auch
nach der 1. Normalform normalisiert.
Hier eine Beispieltabelle, die wir nach allen drei Normalformen normalisieren werden.

Die 1. Normalform
Die Bedingung der 1. Normalform lautet: "Alle Attribute sind atomar".
Atomar bedeutet, dass die Attribute nur einfache Attributwerte beinhalten. Also müssen beispielsweise Namen und
Adressen so weit wie möglich aufgespalten werden. Tun wir dies in der Beispieltabelle, so müssen wir beispielsweise
Künstler und Album und die Titel voneinander trennen, da diese zusammengesetzte Attribute sind.
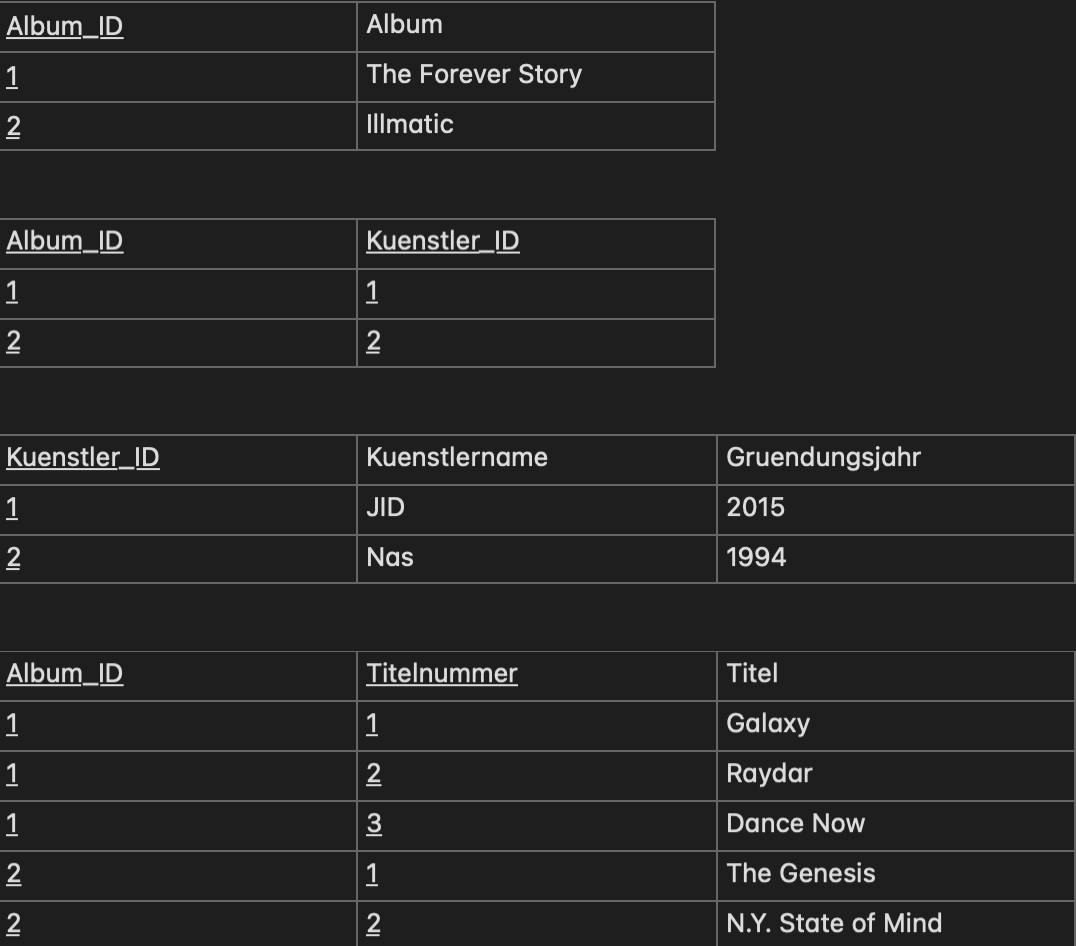
Daraufhin entsteht folgende Tabelle:

Die 2. Normalform
Die Bedingung der 2. Normalform lautet: "Befindet sich in der 1. Normalform und jedes Nicht-Schlüssel Attribut ist
vom Primärschlüssel voll funktional abhängig."
Haben wir einen Primärschlüssel, der aus mehreren Attributen besteht, wie hier aus der Album_ID und Titelnummer, muss
die Tabelle gespalten werden, da bspw. der Künstler nicht von der Titelnummer, folglich nicht vom gesamten
Primärschlüssel abhängig ist.
Machen wir entsprechende Änderungen, erhalten wir folgende Tabellen:
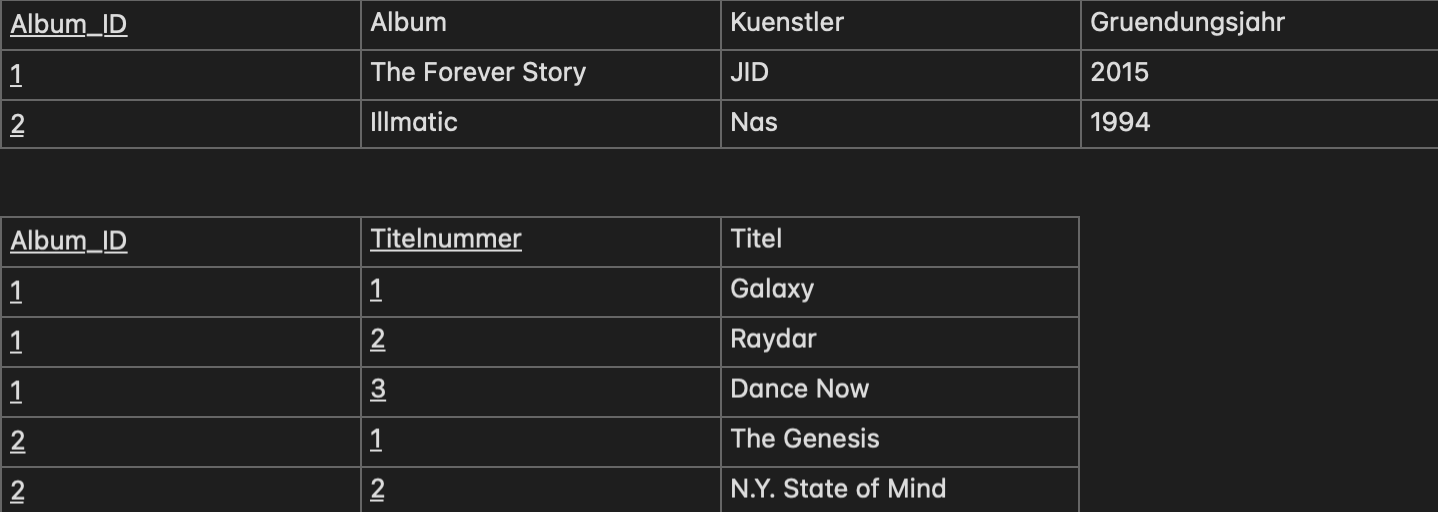
Die 3. Normalform
Die Bedingung der 3. Normalform lautet: "Befindet sich in der 2. Normalform und kein
Nicht-Schlüsselattribut hängt von einem anderen Nicht-Schlüsselattribut ab."
In unserer Tabelle haben wir z.B. jedoch keine Abhängigkeit zwischen dem Gründungsjahr eines Künstlers und der Album_ID.
Ebenfalls ist der Künstler unabhängig von der Album_ID.
Machen wir entsprechende Änderungen, erhalten wir folgende Tabellen: